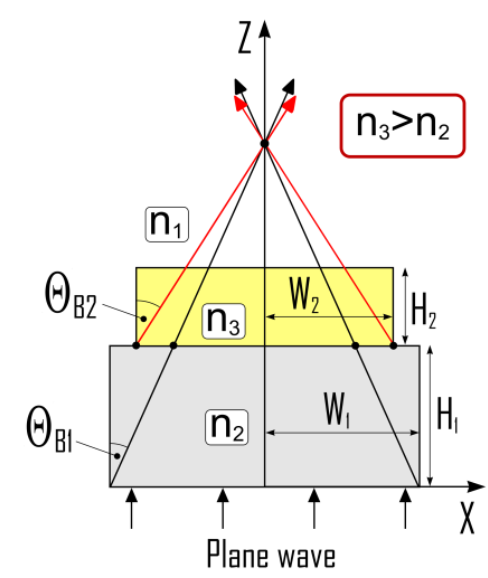
In this contribution we reveal how the step-like topology of a microstructure can contribute to the formation of a single high-intensity nanojet (NJ) beam located on its axis of symmetry. The proposed method for generating condensed optical NJ beams relies on the complex electromagnetic phenomenon associated with the light diffraction on the edges of step-like dielectric microstructures embedded in a host medium with lower refractive index. The possibility of NJ beam intensification in the near zone of such microstructure illuminated by a plane wave is demonstrated and explained by the recombination of multiple NJ beams associated with different edges or edge segments of the step-like microlens. We demonstrate that by changing materials of the layers we can intensify the NJ beam. We examine the dependence of the generated beam on the step size, shape and material.
“Localized photonic jets generated by step-like dielectric microstructures“, O. Shramkova, V. Drazic, M. Damghanian, A. Boriskin, V. Allié, L. Blondé, International Conference on Transparent Optical Networks, 1-5 July 2018, Bucharest, Romania.
Skip to PDF content
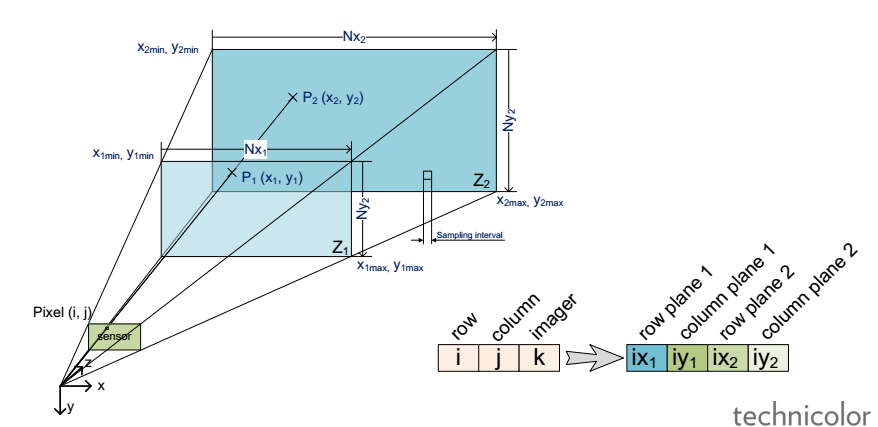
Light-field (LF) is foreseen as an enabler for the next generation of 3D/AR/VR experiences. However, lack of unified representation, storage and processing formats, variant LF acquisition systems and capture-specific LF processing algorithms prevent cross-platform approaches and constrain the advancement and standardization process of the LF information. In this work we present our vision for camera-agnostic format and processing of LF data, aiming at a common ground for LF data storage, communication and processing. As a proof-of-concept for camera-agnostic pipeline, we present a new and efficient LF storage format (for 4D rays) and demonstrate feasibility of camera-agnostic LF processing. To do so, we implement a camera-agnostic depth extraction method. We use LF data from a camera-rig acquisition setup and several synthetic inputs including plenoptic and non-plenoptic captures, to emphasize the camera-agnostic nature of the proposed LF storage and processing pipeline.
“Camera-agnostic format and processing for light-field data“, Mitra Damghanian, Paul Kerbiriou, Valter Drazic, Didier Doyen, Laurent Blondé, 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 10-14 July 2017
Skip to PDF content
Skip to PDF content
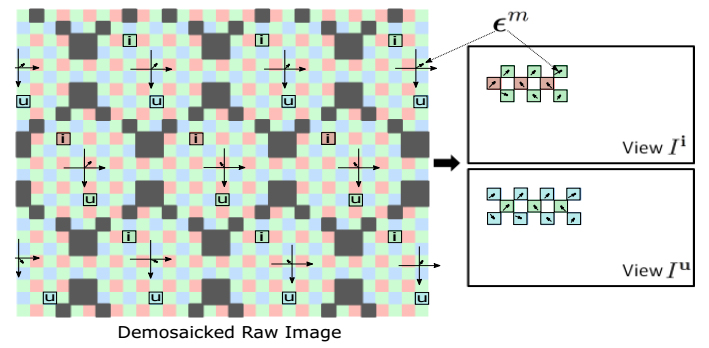
Light field imaging is recently made available to the mass market by Lytro and Raytrix commercial cameras. Thanks to a grid of microlenses put in front of the sensor, a plenoptic camera simultaneously captures several images of the scene under different viewing angles, providing an enormous advantage for post-capture applications, e.g., depth estimation and image refocusing. In this paper, we propose a fast framework to re-grid, denoise and up-sample the data of any plenoptic
camera. The proposed method relies on the prior sub-pixel estimation of micro-images centers and of inter-views disparities. Both objective and subjective experiments show the improved quality of our results in terms of preserving high frequencies and reducing noise and artifacts in low frequency content. Since the recovery of the pixels is independent of one another, the algorithm is highly parallelizable on GPU.
“On plenoptic sub-aperture view recovery“, Mozhdeh Seifi, Neus Sabater, Valter Drazic, Patrick Pérez, 24th European Signal Processing Conference (EUSIPCO), 29 Aug.-2 Sept. 2016
Skip to PDF content

Light-field imaging has been recently introduced to mass market by the hand held plenoptic camera Lytro. Thanks to a microlens array placed between the main lens and the sensor, the captured data contains different views of the scene from different view points. This offers several post-capture applications, e.g., computationally changing the main lens focus. The raw data conversion in such cameras is however barely studied in the literature. The goal of this paper is to study the particularly overlooked problem of demosaicking the views for plenoptic cameras such as Lytro. We exploit the redundant sampling of scene content in the views, and show that disparities estimated from the mosaicked data can guide the demosaicking, resulting in minimum artifacts compared to the state of art methods. Besides, by properly addressing the view demultiplexing step, we take the first step towards light field super-resolution with negligible computational overload.
“Disparity-guided demosaicking of light field images“, M. Seifi, N. Sabater, V. Drazic, P. Perez, IEEE International Conference on Image Processing (ICIP), 2014
Skip to PDF content
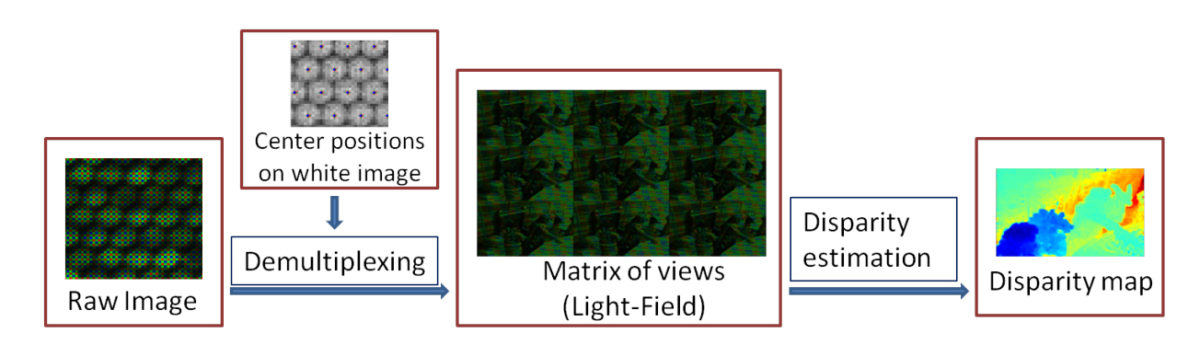
In this paper we propose a post-processing pipeline to recover accurately the views (light-field) from the raw data of a plenoptic camera such as Lytro and to estimate disparity maps in a novel way from such a light-field. First, the microlens centers are estimated and then the raw image is demultiplexed without demosaicking it beforehand. Then, we present a new block-matching algorithm to estimate disparities for the mosaicked plenoptic views. Our algorithm exploits at best the configuration given by the plenoptic camera: (i) the views are horizontally and vertically rectified and have the same baseline, and therefore (ii) at each point, the vertical and horizontal disparities are the same. Our strategy of demultiplexing without demosaicking avoids image artifacts due to view cross-talk and helps estimating more accurate disparity maps. Finally, we compare our results with state-of-the-art methods.
“Accurate Disparity Estimation for Plenoptic Images“, N. Sabater, M. Seifi, V. Drazic, G. Sandri, P. Perez, European Conference on Computer Vision (ECCV) 2014 Workshops.
Skip to PDF content

Generating depth maps along with video streams is valuable for Cinema and Television production. Thanks to the improvements of depth acquisition systems, the challenge of fusion between depth sensing and disparity estimation is widely investigated in computer vision. This paper presents a new framework for generating depth maps from a rig made of a professional camera with two satellite cameras and a Kinect device. A new disparity-based calibration method is proposed so that registered Kinect depth samples become perfectly consistent with disparities estimated between rectified views. Also, a new hierarchical fusion approach is proposed for combining on the flow depth sensing and disparity estimation in order to circumvent their respective weaknesses. Depth is determined by minimizing a global energy criterion that takes into account the matching reliability and the consistency with the Kinect input. Thus generated depth maps are relevant both in uniform and textured areas, without holes due to occlusions or structured light shadows. Our GPU implementation reaches 20fps for generating quarter-pel accurate HD720p depth maps along with main view, which is close to real-time performances for video applications. The estimated depth is high quality and suitable for 3D reconstruction or virtual view synthesis.
“Fusion of Kinect depth data with trifocal disparity estimation for near real-time high quality depth maps generation“, G. Boisson, P. Kerbiriou, V. Drazic, O. Bureller, N. Sabater, A. Schubert. Proc. SPIE 9011, Stereoscopic Displays and Applications XXV, 90110J. IS&T/SPIE Electronic Imaging, 2014.
Skip to PDF content
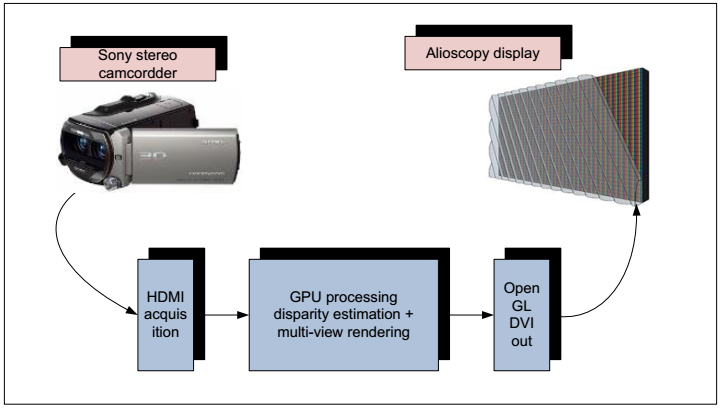
As often declared by customers, wearing glasses is a clear limiting factor for 3D adoption in the home. Auto-stereoscopic systems bring an interesting answer to this issue. These systems are evolving very fast providing improved picture quality. Nevertheless, they require adapted content which are today highly demanding in term of computation power. The system we describe here is able to generate in real-time adapted content to these displays: from a real-time stereo capture up to a real-time multi-view rendering. A GPU-based solution is proposed that ensures a real-time processing of both disparity estimation and multi-view rendering on the same platform.
“A real-time 3D multi-view rendering from a real-time 3D capture”, D. Doyen, S. Thiebaud, V. Drazic, C. Thébault. Vol. 44, N°. 1 July, 578-581, SID 2013
Skip to PDF content

Speed and accuracy in stereo vision are of foremost importance in many applications. Very few authors focus on both aspects and in this paper we propose a new local algorithm that achieves highaccuracy in real-time. Our GPU implementation of a disparity estimator levels with the fastest published so far with 4839 MDE/s (Millions of Disparity Estimation per Second) but is the most precise at that speed. Moreover, our algorithm achieves high-accuracythanks to a reliability criterion in the matching decision rule. A quantitative and qualitative evaluation has been done on the Middlebury benchmark and on real data showing the superiority of our algorithm in terms of execution speed and matching accuracy. Accomplishing such performances in terms of speed and quality opens the way for new applications in 3D media and entertainment services.
“A Precise Real-time Stereo Algorithm“, V. Drazic, N. Sabater, Proceedings of the 27th Conference on Image and Vision Computing New Zealand IVCNZ 2012.
Skip to PDF content
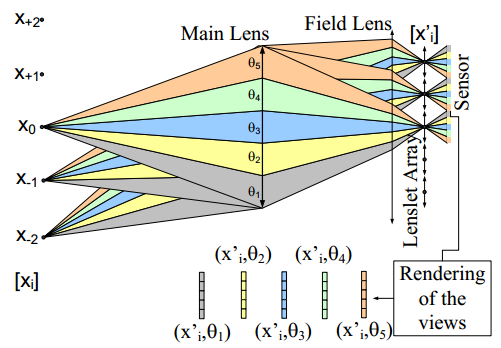
A plenoptic camera is a natural multiview acquisition device also capable of measuring distances by correlating a set of images acquired under different parallaxes. Its single lens and single
sensor architecture have two downsides: limited resolution and limited depth sensitivity. As a first step and in order to circumvent those shortcomings, we investigated how the basic design parameters of a plenoptic camera optimize both the resolution of each view and its depth-measuring capability. In a second step, we built a prototype based on a very high resolution Red One® movie camera with an
external plenoptic adapter and a relay lens. The prototype delivered five video views of 820 × 410. The main limitation in our prototype is view crosstalk due to optical aberrations that reduce the depth accuracy performance. We simulated some limiting optical aberrations and predicted their impact on the performance of the camera. In addition, we developed adjustment protocols based on a simple pattern and analysis of programs that investigated the view mapping and amount of parallax crosstalk on the sensor on a pixel basis. The results of these developments enabled us to adjust the lenslet array with a submicrometer precision and to mark the pixels of the sensor where the views do not register properly.
“Optimal design and critical analysis of a high-resolution video plenoptic demonstrator“, V. Drazic, JJ Sacré, A. Schubert, J. Bertrand, E. Blondé. Proceedings Volume 7863, Stereoscopic Displays and Applications XXII; 786318 (2011) , IS&T/SPIE Electronic Imaging, 2011, San Francisco
Skip to PDF content
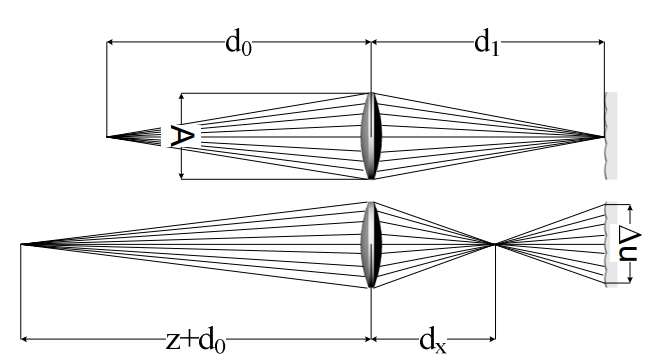
Plenoptic cameras1are able to acquire multi-view content that can be displayed on auto-stereoscopic displays. Depth maps can be generated from the set of multiple views. As it is a single lens system, very often the question arises whether this system is suitable for 3D or depth measurement. The underlying thought is that the precision with which it is able to generate depth maps is limited by the aperture size of the main lens. In this paper, we will explore the depth discrimination capabilities of plenoptic cameras. A simple formula quantifying the depth resolution will be
given and used to drive the principal design choices for a good depth measuring single lens system.
“Optimal Depth Resolution in Plenoptic Imaging“, V. Drazic, IEEE Internacional Conference on Multimedia and Expo, 19-23 July 2010, Singapore (ICMA 2010)
Skip to PDF content